
자료구조
데이터를 효과적으로 관리하기위한 구조와 알고리즘
사용하는 이유 : 특정연산 ( 삽입, 삭제, 검색 ) 등을 효율적으로 수행하여 메모리를 최적으로 활용
사용되는 자료구조 : 배열, 스택, 큐, 리스트, 트리, 그래프, 해시 테이블, 맵 , 셋, 우선순위큐, 힙 등등이 있다
| 배열 (Array) |
| 같은 타입으로 된 여러 객체를 한번에 다루고자 할때 사용 고정된 크기를 가지는 선형 자료구조이다 |
#include <array>
using namespace std;
int main(void)
{
array<int, 4> testArr = { 1, 2, 3, 4 };
}
| 동적 배열 (Dynamic Array) Vector |
| 크기가 동적으로 조절 가능한 선형 자료구조 중간 삽입 / 삭제 가 느리다 메모리 효율이 좋고 캐시 친화적이다 (인덱스로 빠른 탐색 가능) |
#include <vector>
#include <iostream>
using namespace std;
int main(void)
{
vector<int> myVec;
myVec.push_back(1);
myVec.push_back(2);
myVec.push_back(3);
myVec.pop_back();
for (int num : myVec)
{
cout << num << endl;
}
}
| 스택 (Stack) |
| 가장 마지막으로 들어가는 원소가 제일 먼저 나오는 LIFO(Last In First Out)자료구조 |
#include <stack>
#include <iostream>
using namespace std;
int main(void)
{
stack<int> stk;
stk.push(1);
stk.push(2);
stk.push(3);
while (!stk.empty())
{
cout << stk.top() << " ";
stk.pop();
}
}| 큐(Queue) |
| 가장 먼저 들어간 원소가 가장 먼저 나오는 선입선출 FIFO(First In First Out)자료구조 |
#include <queue>
#include <iostream>
using namespace std;
int main(void)
{
queue<int> testQ;
testQ.push(1);
testQ.push(2);
testQ.push(3);
while (!testQ.empty())
{
cout << testQ.front() << " ";
testQ.pop();
}
}
| 연결 리스트(Linked List) |
| 각 노드가 데이터와 포인터를 가지고 한줄로 연결되어있는 방식으로 데이터를 저장하는 자료 구조 중간 삽입 / 삭제가 vector 구조보다 빠르다 단 임의 접근이 불가능하여 처음부터 순회해야함 메모리 효율이 낮음 |
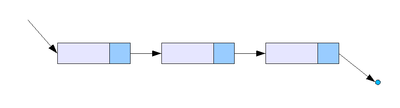


#include <list>
#include <iostream>
using namespace std;
int main(void)
{
list<int> myList;
myList.push_back(1);
myList.push_back(2);
myList.push_back(3);
// 현재 1 2 3 리스트
for (int listNum : myList)
{
cout << listNum << " ";
}
cout << endl;
//뒤 (3) 삭제
myList.pop_back(); // 1 2
//앞 (1) 삭제
myList.pop_front(); // 2
//뒤에 5 추가
myList.push_back(5); // 2 5
//앞에 7 추가
myList.push_front(7); // 7 2 5
//begin()에서 2만큼 이동 -> 세번쨰 원소 삭제
auto it = myList.begin();
advance(it, 2);
myList.erase(it); // 7 2
cout << "삭제 후 리스트: ";
for (int listNum : myList)
{
cout << listNum << " ";
}
cout << endl;
}
| 셋 (Set) |
| 중복을 허용하지 않는 정렬된 자료구조 값만 존재하여 Key가 Value역할을 수행 |
#include <set>
#include <iostream>
using namespace std;
int main(void)
{
set<int> mySet;
mySet.insert(1);
mySet.insert(1);
mySet.insert(1);
mySet.insert(4);
mySet.insert(2);
mySet.insert(5);
for (int myNum : mySet)
{
cout << myNum << " ";
}
}해당 코드를 실행할시 중복된 1은 제외하고 정렬되어 1, 2, 4, 5 가 출력
| 맵 (Map) |
| 중복을 허용하지 않는 정렬된 자료구조 검색, 삽입, 삭제 시 키 기준 정렬 |
#include <map>
#include <iostream>
using namespace std;
int main(void)
{
map<string, int> myMap;
myMap["Apple"] = 5;
myMap["Banana"] = 3;
myMap["Orange"] = 2;
for (auto& kv : myMap)
{
cout << kv.first << ": " << kv.second << endl;
}
}| 힙 (Heap) |
| 완전 이진 트리 기반의 자료구조로 최대값 및 최솟값을 빠르게 찾기 위해 사용 최대힙(루트가 가장 큰값), 최소힙(루트가 가장 작은 값) 이 존재 힙의 조건은 부모 >= 자식 이다 |
#include <algorithm>
#include <vector>
#include <iostream>
using namespace std;
int main(void)
{
vector<int> v;
//최대힙
v = { 10, 20, 30, 40, 50, 60 };
make_heap(v.begin(), v.end());
for (int heapNum : v)
{
cout << heapNum << " ";
}
cout << endl;
//최소힙
v = { 10, 20, 30, 40, 50, 60 };
make_heap(v.begin(), v.end(), greater<int>());
for (int heapNum : v)
{
cout << heapNum << " ";
}
cout << endl;
v = { 10, 20, 30, 40, 50, 60 };
make_heap(v.begin(), v.end()); //최대힙으로 만들기
pop_heap(v.begin(), v.end()); // 가장 큰 값을 끝으로 이동
v.pop_back(); //실제 제거
for (int heapNum : v)
{
cout << heapNum << " ";
}
}
출력값

| Unordered_map |
| 키 - 값 쌍을 저장하는 해시 기반 컨테이너 키 검색, 삽입, 삭제가 시간복잡도 O(1)의 값이 평균적으로 나오는 자료구조 그냥 map과 다른점은 정렬이 되지 안됨, 해시테이블을 사용한다 |
#include <iostream>
#include <unordered_map>
using namespace std;
int main()
{
// 키: string, 값: int
unordered_map<string, int> umap;
umap["apple"] = 5;
umap["banana"] = 3;
umap["orange"] = 7;
cout << "apple: " << umap["apple"] << endl;
for (auto& kv : umap)
{
cout << kv.first << ": " << kv.second << endl;
}
// 삭제
umap.erase("banana");
cout << "삭제 후:" << endl;
for (auto& kv : umap)
{
cout << kv.first << ": " << kv.second << endl;
}
return 0;
}'개인 코테 & 스타디 <비공개> > 알고리즘 스타디 과제' 카테고리의 다른 글
| 농부, 배추, 염소, 늑대 강건너기 (0) | 2025.10.01 |
|---|---|
| 과제 - 재귀함수 계산기 만들기 (0) | 2025.09.24 |